Category: Uncategorized
-

AI Alt Text Writer
When posting images online, adding alt text, or alternative text, helps people who rely on it because for whatever reason they can’t view images. For example, it’s helpful for blind and visually impaired people who rely on screen readers. It also shows up in place of any images that fail to load for whatever reason.…
-

Talk on PRESTO
On Monday I was lucky to give a presentation on “Predicting Rare Events by Shrinking Towards Proportional Odds” at the 90/30 Club. I’m grateful to the current organizers Ryo Sakai, Logan Graves, and Max Phelps for having me, as well as the founder of the group, Lydia Nottingham. I figured this is as good of…
-

Now on CRAN: {fetwfe} version 1.5.0, with new features
Version 1.5.0 of {fetwfe} just hit CRAN. This is the first time I’ve posted about the package since the 0.4.4 blog announcement back in February, although I quietly shipped 1.0.0 to CRAN in May (and many incremental versions on GitHub as well). There have been lots of changes since 0.4.4, and I’ll outline them in…
-

Demo: Retrieval-augmented generation application for customer service
The most common application for retrieval-augmented generation (RAG) is answering questions from a large source, like a codebase, a book, or documentation. I made a Colab notebook that demonstrates both a basic RAG workflow and a different use case: customer service. Customer service teams often receive repetitive questions that require near-identical answers. The classic way…
-
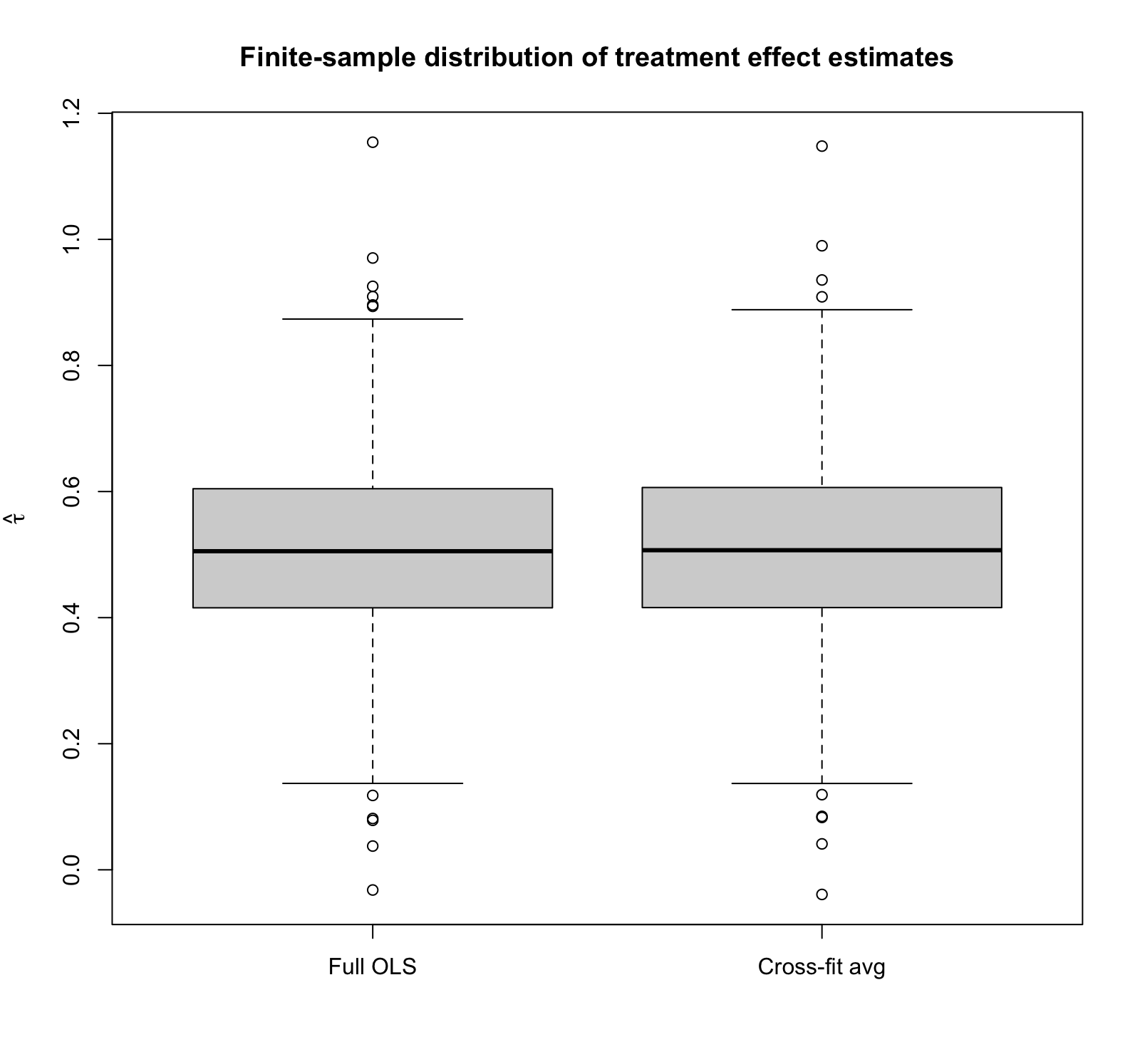
Estimating treatment effects with a linear model in a randomized experiment–insights from the Double/Debiased ML framework
When treatment assignment is randomized, one model that people often use for estimating treatment effects is (sometimes called the ANCOVA II model), where is the binary treatment indicator (1 if unit is treated, 0 if not), is a vector of covariates for unit , and is the sample mean of the covariates. Theorem 7.2 of…
-

Presentation at the Advertising Research Foundation’s AUDIENCExSCIENCE Conference
On Tuesday, I gave a talk (jointly with Katy Mitchell) titled “Innovations in Cross-Screen Incremental Outcome Measurement” at the Advertising Research Foundation‘s 2025 AUDIENCExSCIENCE Conference. The main topic was the methodology I’ve been developing at VideoAmp for measuring incremental conversions for a particular digital platform. This methodology uses observational causal inference techniques to estimate incremental…
-

The {fetwfe} R package is now available on CRAN!
{fetwfe} is now available on CRAN! You can now install {fetwfe} by simply using You can always access the latest development version using In the process of preparing the package for CRAN, I also fixed a couple little bugs and edge cases from the original version. As always, feel free to reach out with any…
-
New R {fetwfe} Package Implementing Fused Extended Two-Way Fixed Effects
I’m excited to announce that an R package {fewtfe} implementing fused extended two-way fixed effects is now available on my GitHub! To install it, simply use The function fetwfe() in the package takes in a panel data set and does the following for you: See the specifications for the inputs and outputs on the GitHub…
-
Causal Inference Notation and Concepts
In this post, I’m going to expand on the basics I laid out more informally here. I’m going to define some commonly used notation and key terms that I plan to use as other posts, so that this post can serve as a reference in the future. I may also add to it over time…
-

Explaining vs. Predicting
I came across two nice written pieces recently. These and other closely related points have been made for a long time, and I’ve made related points before. I think it’s an underappreciated and somewhat counterintuitive point, so I like to harp on this a little. When people seek to answer questions from data by using…