The R package {cssr} is back in active development. The previous update was in January 2025 to version 0.1.8, and there hadn’t been significant changes since 2023. Over the past couple of weeks I’ve put it through a round of robustness fixes, much-expanded documentation, and a top-to-bottom review of the code against the paper. No methodology changes, but the existing implementation is safer to use, easier to learn, and easier to trust.
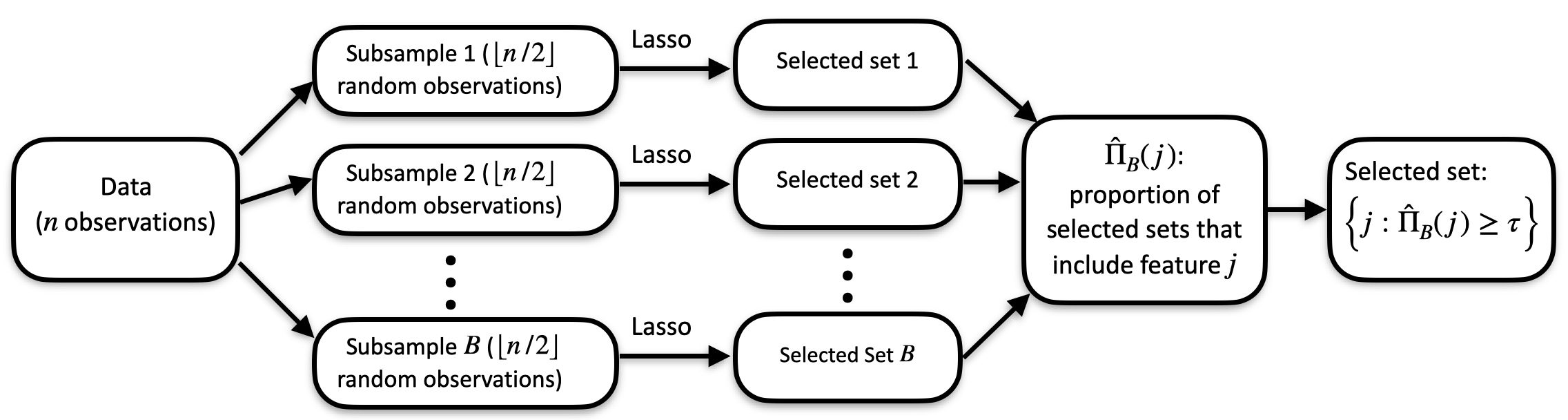
(If you’re new to the package, {cssr} implements cluster stability selection, a feature-selection method for data with clusters of highly correlated features. Ordinary stability selection runs into a “vote-splitting” problem when several features are near-duplicates of the same underlying signal: each one gets a small selection proportion, so none of them is chosen, even when the cluster as a whole is important. Cluster stability selection tracks how often a cluster is selected rather than how often each individual feature is, so correlated proxies stop competing with one another. The website has a more complete explanation and the paper (Faletto and Bien 2022) has the details.)
Install
{cssr} lives on GitHub. The package source is in the cssr subdirectory, so install it with:
# install.packages("remotes") # if needed
remotes::install_github("gregfaletto/cssr-project", subdir = "cssr")A quick example
The package ships its own data simulator, so the setup is self-contained. Here we generate 80 observations of 40 features, where the first 10 columns are a cluster of correlated proxies for one latent signal, and ask cssSelect() to select features — telling it about the cluster:
library(cssr)
set.seed(983219)
data <- genClusteredData(n = 80, p = 40, cluster_size = 10,
k_unclustered = 10, snr = 3)
out <- cssSelect(data$X, data$y, clusters = list(Z_cluster = 1:10))
out$selected_clusts$Z_cluster
[1] 1 2 3 4 5 6 7 8 9 10
$c2
[1] 11
$c3
[1] 12
$c4
[1] 13
$c7
[1] 16The whole correlated cluster is selected as a single unit (alongside a few of the individually relevant features), which is exactly the behavior plain stability selection struggles to produce.
What’s new in 0.2.0
In brief:
- Fail-fast input checking — missing or non-finite values, and other malformed inputs, now raise a clear error instead of silently producing wrong results.
- Two new vignettes (a prediction walkthrough and an advanced-usage guide), plus runnable examples on every exported function.
- A cleaner, more readable companion book that documents the package internals.
- A top-to-bottom review of the code against the paper, and the batch of fixes and cleanups it produced.
- Reproducible builds and a test suite of over 3,700 checks.
Safer inputs
The change most likely to affect you is stricter input checking. The package used to let some bad inputs through and quietly compute something meaningless. The most important case: a non-finite value (an Inf or a stray NA) in the feature matrix or the response would slip past the old check and flow into the model fit, silently corrupting the selection proportions — and, for the response, doing so non-deterministically, because part of the procedure runs on a random sub-sample, so the same call could error on one run and return a plausible-looking answer on the next. Both the feature matrix and the response are now checked up front:
X <- data$X
X[3, 5] <- Inf
cssSelect(X, data$y, clusters = list(Z_cluster = 1:10))Error: The provided X must not contain missing (NA) or non-finite (Inf)
values; please remove or impute them before calling this function.More generally, the entry points now validate their arguments earlier and explain what went wrong, accept a data.frame wherever they accept a matrix, and give actionable messages for degenerate inputs (too few observations, out-of-range cluster indices, dimension mismatches between training and test data) rather than failing later with a cryptic internal assertion.
More documentation
The package’s tutorial was incomplete — it covered feature selection but trailed off before prediction. There are now two vignettes:
vignette("prediction", "cssr") # predicting with cluster representatives
vignette("advanced-usage", "cssr") # competitor methods, generators, helpersThe first walks through making predictions from selected clusters — forming weighted cluster representatives and the three weighting schemes (simple_avg, weighted_avg, sparse). The second covers the competitor methods the paper compares against (protolasso(), clusterRepLasso()), the data generators used in the simulation studies, and the smaller helper functions. On top of that, every one of the package’s exported functions now has a runnable @examples block, and the companion book that defines the package via literate programming has been reorganized so the exposition reads as continuous prose instead of being interrupted by long stretches of tests.
Feedback
As always, feel free to open or upvote an issue at github.com/gregfaletto/cssr-project/issues if you have any questions, concerns, or requests for the package. You can also reach out to me directly.
Leave a Reply