Version 1.10.0 of {fetwfe} is now available on CRAN. Since the previous CRAN version, 1.5.0, I’ve added a handful of new features, a correction to the standard errors that’s worth knowing about if you upgrade, and a lot of internal cleanup. This post covers the updates.
(If you’re new to the package, {fetwfe} implements fused extended two-way fixed effects, an estimator for difference-in-differences with staggered treatment adoption. Conventional two-way fixed effects is biased under staggered adoption; FETWFE isn’t, and it uses regularization to keep variance down while still producing valid standard errors. The paper has the details.)
Install or upgrade
To get the stable CRAN release:
install.packages("fetwfe")You can always get the development branch as well, which updates more frequently:
# install.packages("remotes") # if needed
remotes::install_github("gregfaletto/fetwfePackage")Setting up the examples
The snippets below all reuse one fitted object, result. The package ships its own simulators, so the setup is self-contained — genCoefs() builds a coefficient vector, simulateData() draws a panel from it, and fetwfeWithSimulatedData() fits the estimator.
library(fetwfe)
set.seed(1)
sim_coefs <- genCoefs(R = 3, T = 6, d = 2, density = 0.5, eff_size = 2)
sim_data <- simulateData(sim_coefs, N = 120, sig_eps_sq = 1, sig_eps_c_sq = 0.5)
result <- fetwfeWithSimulatedData(sim_data, verbose = FALSE)
summary(result)That fits a panel of 120 units over 6 periods with three treatment cohorts, and summary() prints the headline estimates:

What’s new since 1.5.0
In brief:
eventStudy()andplot()methods, for event-study estimates and plots.tidy(),glance(), andaugment()methods, so results work with thebroompackage.- Per-cohort p-values and selection flags for testing whether an effect is zero.
- An experimental cluster-robust standard-error option.
- Panels with no never-treated units no longer error out.
- A correction to the standard-error estimation.
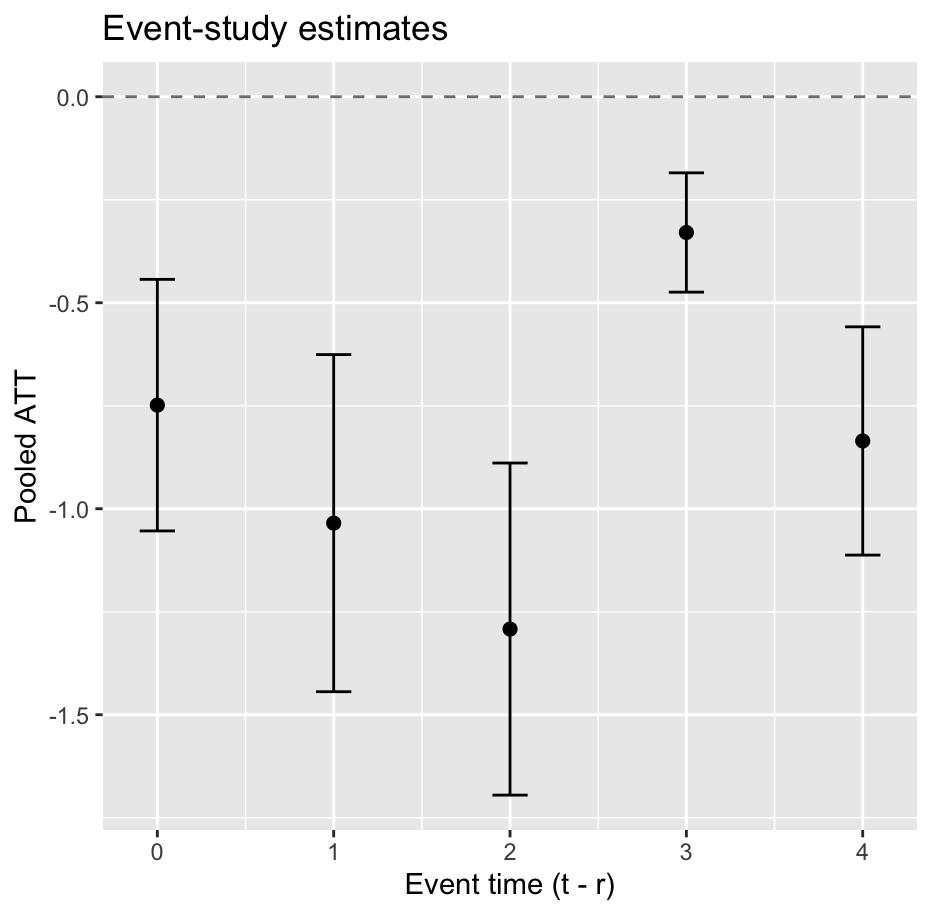
Event-study estimates and plots
{fetwfe} has always reported an overall ATT and a separate effect for each treatment cohort. eventStudy() pools those into estimates by event time — the number of periods since treatment began — with confidence intervals:
eventStudy(result)
The new plot() methods draw the event-study plot directly from a fitted object:
plot(result)
That returns a ggplot object with one point and confidence interval per event time. An event-study plot is usually the first thing you want from a staggered-adoption analysis, so this saves a step.
Tidy output with broom
If you use the tidyverse, {fetwfe} results now work with broom. tidy() returns a long data frame with the standard term / estimate / std.error / conf.low / conf.high columns:
library(broom)
tidy(result)
glance() gives a one-row model summary, and augment() adds fitted values and residuals to your panel:
glance(result)
augment(result, data = sim_data$pdata)

So you can hand the output straight to ggplot2 or modelsummary without learning the package’s own object layout.
Testing whether an effect is zero
Difference-in-differences users usually want to know whether an effect is distinguishable from zero. {fetwfe} now reports a p-value for every cohort and for the overall ATT. For fetwfe() and betwfe() there’s also a selected flag — and that flag says something a confidence interval can’t. Because of FETWFE’s selection-consistency property, a cohort that gets selected out is, asymptotically, an estimate of exactly zero — a stronger statement than “not significantly different from zero.” Both columns are in result$catt_df (and in the tidy() output above):
result$catt_df
Here cohorts 2 and 4 survive selection and get a p-value; cohort 3 was selected out, so its estimate is exactly zero and P_value is NA — the inferential content is in selected. A new vignette section explains how to read the p-value and the flag together.
Experimental cluster-robust standard errors
Every estimator now takes a se_type = "cluster" option, which replaces the default (Assumption-F1-based) standard errors with a unit-clustered sandwich estimator:
result_cluster <- fetwfeWithSimulatedData(
sim_data, verbose = FALSE, se_type = "cluster"
)
result$att_se # default standard error
result_cluster$att_se # cluster-robust standard error[1] 0.1851252
[1] 0.1894The theory behind it isn’t finished yet, so treat it as a sensitivity check, not a default. The inference vignette spells out which assumptions it relaxes and where the caveats are.
Panels with no never-treated units
FETWFE compares treated units against not-yet-treated and never-treated units. A panel with no never-treated units at all used to be a hard error. Now, with allow_no_never_treated = TRUE (the default), the package drops the latest time periods so the final cohort can serve as the comparison group, and warns you about exactly what it dropped.
To see it, take the panel from above and mark its never-treated units as treated in the last period, so no unit is ever a never-treated control:
panel <- sim_data$pdata
treated_units <- unique(panel$unit[panel$treatment == 1])
never_treated <- setdiff(unique(panel$unit), treated_units)
panel$treatment[panel$unit %in% never_treated &
panel$time == max(panel$time)] <- 1L
result_trunc <- fetwfe(
pdata = panel, time_var = "time", unit_var = "unit",
treatment = "treatment", response = "y", covs = c("cov1", "cov2")
)The fit still goes through, after a warning naming the dropped period:
Warning message:
No never-treated units in input data; auto-truncated panel by dropping time
periods at or after 6 (dropped: 6). The units that started treatment at 6
serve as the never-treated comparison group in the truncated panel. Set
`allow_no_never_treated = FALSE` to disable this behavior.Set allow_no_never_treated = FALSE if you’d rather it error out instead.
A correction to the standard errors
One change is worth being explicit about. Version 1.9.1 fixed a bug in how {fetwfe} estimated its variance components. The old code collapsed the unit-level variance to roughly zero, so the package treated clustered panel noise as if it were independent. The fix estimates those components properly, by REML, so the generalized-least-squares step the estimator depends on now actually does its job.
If you upgrade, expect both your standard errors and your point estimates to change. Standard errors usually go up on panels with real unit-level variation; point estimates move because the corrected weighting changes the regression underneath. This is a bug fix, not a change to the method — it brings the implementation in line with what the paper describes. If you have results from an older version of the package, re-run them. The main vignette has a worked example. See details on the previous bugs and the impact of the fixes in the relevant pull requests on Github.
Feedback
As always, feel free to open or upvote an issue at github.com/gregfaletto/fetwfePackage/issues if you have any questions, concerns, or requests for the package. You can also reach out to me directly.