Author: gfaletto
-

Confidence Intervals
On Friday, I responded to a prompt on the platform formerly known as Twitter asking for controversial statistics opinions. I offered one of my own: This take did prove controversial—I saw people some people I consider very smart who agreed with me and some who disagreed. In light of the discussions, I think I have…
-
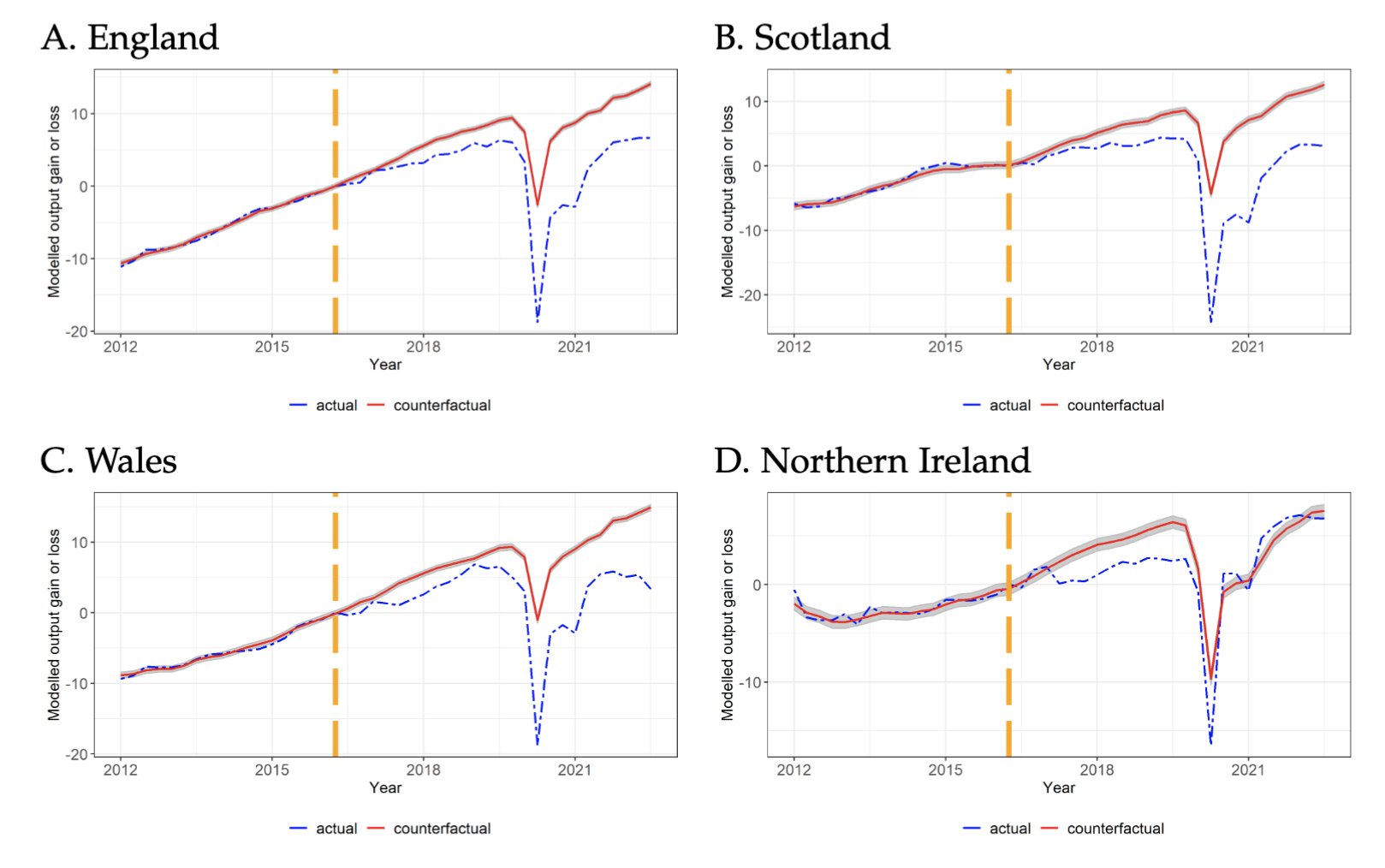
Causal Inference Basics
The goal of causal inference is to understand the effect of an intervention. We want to estimate the difference between what happens if people receive a treatment compared to what would have happened if they hadn’t been treated. Some examples of this include: Why Is Estimating Causal Effects Tricky? Let’s focus on the multivitamin example.…
-

Workshop for Ukraine: Conducting Synthetic Data Experiments in R
On Thursday, I led a workshop on conducting synthetic data experiments (simulation studies) in R to raise money to support Ukraine. It was a lot of fun walking through what simulations studies are, why you might want to conduct one, and how to do the process from start to finish using the R simulator package.…
-

New Draft of “Fused Extended Two-Way Fixed Effects for Difference-in-Differences With Staggered Adoptions”
I’m excited to share that I posted an update to “Fused Extended Two-Way Fixed Effects for Difference-in-Differences With Staggered Adoptions” on arXiv. Mainly what’s new in this draft is added theory, but there are some other minor changes. The most notable change to the exposition (in my opinion) is that I revised my introduction of…
-

Presentation on Fused Extended Two-Way Fixed Effects
On Thursday, I was lucky to present Fused Extended Two-Way Fixed Effects to the causal inference reading group at USC. I’m very grateful to Angela Zhou, Zijun Gao, and Dennis Shen for hosting me, Jacob Bien for putting me in touch with the hosts and coordinating, and everyone who came for their attention and insightful…
-

New Paper: “Fused Extended Two-Way Fixed Effects for Difference-in-Differences with Staggered Adoptions”
I have a new paper on arXiv (link) that proposes a novel machine learning estimator for difference-in-differences with staggered adoptions, fused extended two-way fixed effects (FETWFE). Its main advantage over existing methods is that it is more efficient. Unlike existing methods, it leverages our knowledge that treatment effects for nearby times are likely to be…
-

Presentation at Data Con LA 2023 on PRESTO
On Saturday I gave the presentation “Predicting Purchases, Rare Diseases, and More: Using Ordinal Regression to Estimate Rare Event Probabilities” at Data Con LA 2023. I discussed using the proportional odds ordinal regression model to improve the estimation of probability estimates in classification with class imbalance. I built up to discussing PRESTO, the method developed…
-

How to conduct a synthetic data experiment
Simulation studies (sometimes called synthetic data experiments or Monte Carlo simulations) are useful tools for generating evidence about whether a statistical claim is true. For example: Here’s the idea: Recently I taught a tutorial on the basics on simulation studies for undergraduate students as a part of the USC JumpStart program. I taught the basics…
-

PRESTO accepted to ICML 2023
I’m excited to announce that “Predicting Rare Events by Shrinking Towards Proportional Odds” has been accepted to the Fortieth International Conference on Machine Learning (ICML 2023)! In the paper, we propose PRESTO, a novel method for improving classification in the class imbalance setting. You can read my brief summary of the paper on Twitter.
-

cssr R Package
In a 2022 research paper that I wrote with my advisor Jacob Bien, we proposed a novel feature selection method called cluster stability selection. Cluster stability selection is a method for identifying features that are useful for predicting a response variable. It has applications in medical research (including genomics and genetics), economics, analyzing survey data,…